Concept
Pinot은 대규모 데이터 셋에서 짧은 지연시간 쿼리를 제공하도록 설계되었습니다. 이 성능을 달성하기 위해 Pinot은 데이터를 columnar format으로 저장하고 추가 인덱스를 추가하여 빠른 필터링, 집계 및 그룹화를 수행합니다.
raw data는 small data shards로 나뉩니다. 각 shard는 segment(세그먼트)라는 단위로 변환됩니다. 하나 이상의 세그먼트가 table(테이블)이라는 단위로 형성됩니다. 이 테이블은 SQL/PQL을 사용하여 Pinot에서 쿼리하기 위한 논리적 컨테이너입니다.
Pinot storage model
아래 용어는 Pinot의 스토리지 모델 및 인프라 구성 요소를 설명합니다.

Segment
Pinot에는 수평으로 확장되는 분산 시스템 아키텍처를 가지고 있습니다. Pinot은 테이블의 크기가 시간이 지남에 따라 무한대로 커질 것으로 예상합니다. 이를 달성하려면 모든 데이터가 여러 노드에 분산되어야 합니다. Pinot은 데이터를 segmentI(세그먼트)라는 더 작은 청크로 분할하여 이를 달성합니다. (고가용성(HA) 관계형 데이터베이스의 샤드/파티션과 유사) 세그먼트를 설명하는 또 다른 방법은 시간 기반 파티션입니다.
Table
기존 데이터베이스와 유사하게 Pinot에e도 table의 개념이 있습니다. - 관련된 데이터 모음을 나타내는 논리적 추상화
RDBMS(관계형 데이터베이스 관리 시스템)의 경우와 마찬가지로 테이블은 SQL을 사용하여 쿼리되는 열과 행(문서)으로 구성된 구조입니다. 테이블은 테이블의 열과 해당 데이터 유형을 정의하는 스키마와 연결됩니다.
RDBMS 스키마와 달리 Pinot(실시간 또는 배치)의 여러 테이블은 단일 스키마 정의를 상속할 수 있습니다. 테이블은 인덱싱 전략, 파티셔닝, 테넌트, 데이터 원본 또는 복제와 같은 문제에 대해 독립적으로 구성됩니다.
Tenant
multi-tenancy를 지원하기 위해 Pinot은 테넌트에 대한 일류 지원을 제공합니다. 테이블은 테넌트와 연결됩니다. 이를 통해 특정 논리적 네임스페이스에 속하는 모든 테이블을 단일 테넌트 이름으로 그룹화하고 다른 테넌트와 격리할 수 있습니다. 테넌트 간의 이러한 격리는 테이블 또는 스키마 공유를 방지하기 위해 애플리케이션 및 팀에 대해 서로 다른 네임스페이스를 제공합니다. 응용 프로그램을 구축하는 개발 팀은 Pinot의 독립적인 배포를 운영할 필요가 없습니다. 조직은 단일 클러스터를 운영하고 새 테넌트가 전체 쿼리 볼륨을 증가시키면 클러스터를 확장할 수 있습니다. 개발자는 클러스터의 다른 테넌트의 영향을 받지 않고 자신의 스키마와 테이블을 관리할 수 있습니다.
기본적으로 모든 테이블은 "default"라는 기본 테넌트에 속합니다. 테넌트의 개념은 많은 독립적인 데이터 저장소를 운영하지 않고도 "서비스/응용 프로그램별 데이터베이스"라는 아키텍처 원칙을 충족하므로 매우 중요합니다. 또한 테넌트는 세그먼트(샤드)가 지정된 노드 집합에만 있는 테이블의 데이터를 제한할 수 있도록 리소스를 예약합니다. Linux 컨테이너에서 유비쿼터스로 사용되는 종류의 격리와 마찬가지로 Pinot의 컴퓨팅 리소스는 테넌트 간의 리소스 경합을 방지하도록 예약할 수 있습니다.
Cluster
논리적으로 클러스터는 단순히 테넌트 그룹입니다. 클러스터의 고전적인 정의와 마찬가지로 컴퓨팅 노드 세트의 그룹화이기도 합니다. 일반적으로 환경/데이터 센터당 하나의 클러스터만 있습니다. Pinot은 테넌트 개념을 지원하므로 여러 클러스터를 만들 필요가 없습니다. LinkedIn에서 가장 큰 Pinot 클러스터는 데이터 센터에 분산된 1000개 이상의 노드로 구성됩니다. 클러스터의 노드 수는 쿼리의 성능과 가용성을 선형적으로 증가시키는 방식으로 추가할 수 있습니다. 노드 수와 노드당 컴퓨팅 리소스는 Pinot 클러스터의 QPS를 안정적으로 예측하므로 최종 사용자 애플리케이션에 대한 성능 기대치를 주장하는 SLA를 사용하여 용량 계획을 쉽게 달성할 수 있습니다.
Pinot components

Pinot 클러스터는 여러 분산 시스템 구성 요소로 구성됩니다. 이러한 구성 요소는 시스템 사용량을 모니터링하거나 클러스터 배포와 관련된 문제를 디버깅하는 운영자에게 유용합니다.
- Controller
- Broker
- Server
- Minion (optional)
Pinot은 Apache Zookeeper와 Appache Helix와의 통합을 통해 무한한 수의 노드에 대해 선형 확장이 가능합니다.
Helix는 LinkedIn의 Pinot 작성자가 설계하고 만든 클러스터 관리 솔루션입니다. Helix는 Pinot 클러스터의 상태를 임시 상태에서 이상적인 상태로 만들어 일관성을 보장하는 내결함성 분산 상태 저장소 역할을 합니다. Helix는 컨트롤러, 브로커 및 서버 내에서 작동하는 에이전트로 내장되어 있으며 독립적이고 수평적으로 확장되는 구성 요소로 존재하지 않습니다.
Controller
컨트롤러는 Pinot 클러스터에서 일관성(consistency)과 라우팅(routing)을 책임지는 핵심 오케스트레이터입니다. 컨트롤러는 독립적인 구성 요소(컨테이너)로 수평적으로 확장되며 클러스터에 있는 다른 모든 구성 요소의 상태를 볼 수 있습니다. 컨트롤러는 시스템의 상태 변경에 반응하고 응답하며 테이블, 세그먼트 또는 노드에 대한 리소스 할당을 예약합니다. 앞서 언급했듯이 Helix는 다른 구성 요소가 구독하는 상태 변경을 관찰하고 구동하는 책임이 있는 참여자로서 컨트롤러에 내장되어 있습니다.
클러스터 관리, 리소스 할당 및 예약 외에도 컨트롤러는 Pinot 배포의 REST API 관리를 위한 HTTP 게이트웨이이기도 합니다. 운영자가 SQL/PQL 쿼리를 빠르고 쉽게 실행할 수 있도록 웹 기반 쿼리 콘솔도 제공됩니다.
Broker
브로커는 통합된 응답을 반환하기 전에 클라이언트로부터 쿼리를 수신하고 실행을 하나 이상의 Pinot 서버로 라우팅합니다.
Server
서버는 여러 노드에 걸쳐 예약 및 할당되고 테넌트에 할당 시 라우팅되는 세그먼트(샤드)를 호스트합니다(기본적으로 단일 테넌트가 있음). 서버는 수평으로 확장되는 독립적인 컨테이너이며 컨트롤러에 의해 구동되는 상태 변경을 통해 Helix에 의해 통지됩니다. 서버는 실시간 서버이거나 오프라인 서버일 수 있습니다.
실시간 서버와 오프라인 서버는 리소스 사용 요구 사항이 매우 다릅니다. 실시간 서버는 테넌트의 세그먼트에서 수집 및 할당되는 외부 시스템(예: Kafka 항목)의 새 메시지를 지속적으로 소비합니다. 이 때문에 리소스 격리를 사용하여 수집된 후 브로커를 통해 쿼리에 사용할 수 있는 처리량이 높은 실시간 데이터 스트림의 우선 순위를 지정할 수 있습니다.
Minion
Pinot minion은 GDPR(일반 데이터 보호 규정)에 대한 "제거"와 같은 백그라운드 작업을 실행하는 데 사용할 수 있는 선택적 구성 요소입니다. Pinot은 변경 불가능한 집계 저장소이므로 민감한 개인 데이터가 포함된 레코드는 요청별로 제거해야 합니다. Minion은 GDPR을 준수하는 동시에 Pinot 세그먼트를 최적화하고 데이터 삭제 가능성이 있는 경우 성능을 보장하는 추가 인덱스를 구축하는 이러한 목적을 위한 솔루션을 제공합니다. 주기적으로 실행되는 사용자 지정 작업을 작성할 수도 있습니다. Pinot 서버에서 이러한 작업을 직접 수행할 수 있지만 별도의 프로세스(Minion)가 있으면 세그먼트가 변경 가능한 쓰기의 영향을 받기 때문에 쿼리 대기 시간의 전반적인 저하가 줄어듭니다.
Architecture
Pinot의 분산 시스템 아키텍처에서 쿼리가 계산되는 방법 알아보기
이번에는 Apache Pinot 설계의 기본 원칙을 소개합니다. 여기에서 Pinot이 클러스터의 노드 수에 따라 선형적으로 쿼리 성능을 확장할 수 있도록 하는 분산 시스템 아키텍처를 배웁니다. 또한 오프라인(배치) 또는 실시간(스트림) 모드에서 데이터를 수집하고 쿼리하는 데 사용되는 두 가지 유형의 테이블에 대해 알아봅니다.
Guiding design principles
LinkedIn과 Uber의 엔지니어는 클러스터의 노드 수에 따라 쿼리 성능을 확장하도록 Pinot을 설계했습니다. 더 많은 노드를 추가하면 초당 예상 쿼리 볼륨 할당량에 따라 쿼리 성능이 향상됩니다. 성능 저하 없이 무한한 수의 노드 및 데이터 스토리지에 대한 수평적 확장성을 달성하기 위해 다음 원칙을 사용했습니다.
- 고가용성(Highly available): Pinot은 고객 대면 애플리케이션에 짧은 대기 시간 분석 쿼리를 제공하도록 구축되었습니다. 설계상 Pinot에는 단일 실패 지점이 없습니다. 시스템은 노드가 다운될 때 계속해서 쿼리를 제공합니다.
- 수평 확장 가능(Horizontally scalable): Pinot은 워크로드 변경에 따라 새 노드를 추가하여 확장됩니다.
- 대기 시간 대 스토리지(Latency vs storage): Pinot은 높은 처리량에서도 낮은 대기 시간을 제공하도록 구축되었습니다. 이를 달성하기 위해 세그먼트 할당 전략, 라우팅 전략, 스타 트리 인덱싱과 같은 기능이 개발되었습니다.
- 불변 데이터(Immutable data): Pinot은 저장된 모든 데이터가 불변이라고 가정합니다. GDPR 준수를 위해 성능 보장을 유지하면서 데이터를 제거하기 위한 애드온 솔루션을 제공합니다.
- 동적 구성 변경(Dynamic configuration changes): 새 테이블 추가, 클러스터 확장, 데이터 수집, 인덱싱 구성 수정 및 재조정과 같은 작업은 쿼리 가용성 또는 성능에 영향을 미치지 않아야 합니다.
Core components
concept에서 설명한 것처럼 Pinot에는 컨트롤러, 브로커, 서버 및 미니언과 같은 여러 분산 시스템 구성 요소가 있습니다.
Pinot은 클러스터 관리를 위해 Apache Helix를 사용합니다. Helix는 다양한 구성 요소 내에 에이전트로 내장되어 있으며 전체 클러스터 상태를 조정하고 유지 관리하기 위해 Apache Zookeeper를 사용합니다.

Apache Helix and Zookeeper
분산 시스템에서 파티션과 복제본을 관리하는 일반 클러스터 관리 프레임워크인 Helix는 모든 Pinot 서버와 브로커를 관리합니다. Helix를 클러스터 상태를 이상적인 구성으로 만드는 푸시 및 풀 알림이 포함된 이벤트 기반 검색 서비스로 생각하면 도움이 됩니다. 유한 상태 머신은 클러스터의 상태를 최적의 구성으로 이끄는 상태 저장 작업 계약을 유지합니다. Helix는 데이터가 클러스터에 저장된 위치에 따라 노드 간의 라우팅 구성을 업데이트하여 쿼리 로드를 최적화합니다.
Helix는 노드를 책임에 따라 세 가지 논리적 구성 요소로 나눕니다.
- Participant (참여자): 분산 스토리지 리소스를 실제로 호스트하는 클러스터의 노드입니다.
- Spectator (관람자): 이 노드는 각 참가자의 현재 상태를 관찰하고 그에 따라 요청을 라우팅합니다. 예를 들어 라우터는 요청을 적절한 끝점으로 라우팅하기 위해 파티션이 호스팅되는 인스턴스와 상태를 알아야 합니다. 라우팅은 스토리지 프리미티브가 추가되고 변경됨에 따라 클러스터 성능을 최적화하기 위해 지속적으로 업데이트됩니다.
- Controller (컨트롤러): 컨트롤러는 참여 노드의 상태를 관찰하고 관리합니다. 컨트롤러는 클러스터의 모든 상태 전환을 조정하고 클러스터 안정성을 유지하면서 상태 제약 조건이 충족되도록 합니다.
Helix는 Zookeeper를 사용하여 클러스터 상태를 유지합니다. Pinot 클러스터의 각 구성 요소는 Zookeeper 주소를 시작 매개변수로 사용합니다. Pinot 클러스터에 분산된 다양한 구성 요소는 내장된 Helix 정의 에이전트를 통해 Zookeeper 알림 및 문제 업데이트를 감시합니다.
| Component | Helix Mapping |
| Segment | Helix Partition으로 모델링. 각 세그먼트에는 replicas라고 하는 여러 복사본이 있을 수 있습니다. |
| Table | Helix Resource으로 모델링. 여러 세그먼트는 테이블로 그룹화됩니다. Pinot table에 속한 모든 세그먼트는 같은 스키마를 가집니다. |
| Controller | 클러스터의 전체 상태를 관리하는 Helix agent가 내장되어 있습니다. |
| Server | Helix Participant으로 모델링 되고 세그먼트들을 호스트합니다. |
| Broker | 클러스터에서 세그먼트 및 서버 상태의 변화를 관찰하는 Helix Spectator로 모델링됩니다. multi-tenancy를 지원하기위해 브로커도 Helix 참여자로 모델링됩니다. |
| Minion | Helix Participant로 모델링됩니다. |
Helix 에이전트는 Zookeeper를 사용하여 구성을 저장 및 업데이트하고 분산조정을 수행합니다. Zookeeper는 클러스터에 대한 다음 정보를 저장합니다.
| Resource | Stored Properties |
| Controller | 현재 leader로 할당딘 컨트롤러 |
| Servers/Brokers | - 서버/브로커 목록 및 구성 - Health status |
| Tables | - 테이블 목록 - 테이블 설정정보 - 테이블 스키마 정보 - 테이블에 포함된 세그먼트 리스트 |
| Segment | - 세그먼트(라우팅테이블)의 정확한 서버 위치 - 각 세그먼트의 상태 (online/offline/error/consuming) - 각 세그먼트에 대한 메타데이터 |
Controller
Pinot의 컨트롤러는 클러스터의 전체 상태 및 상태의 드라이버 역할을 합니다. 다른 구성 요소의 상태를 구동하는 Helix 참가자 및 관람자로서의 역할 때문에 일반적으로 Zookeeper 이후에 시작되는 첫 번째 구성 요소입니다.
컨트롤러를 시작하려면 Zookeeper 주소와 클러스터 이름이라는 두 가지 매개변수가 필요합니다. 컨트롤러는 아직 존재하지 않는 경우 Helix를 통해 클러스터를 자동으로 생성합니다.
Fault tolerance
내결함성을 구성하려면 여러 컨트롤러(일반적으로 3개)를 시작하면 그 중 하나가 리더 역할을 합니다. 리더가 충돌하거나 죽으면 다른 리더가 자동으로 선출됩니다. 리더 선출은 Apache Helix를 사용하여 수행됩니다. 테이블 또는 세그먼트 추가와 같이 클러스터에서 DDL에 해당하는 작업을 수행하려면 하나 이상의 컨트롤러가 있어야 합니다.
컨트롤러는 쿼리 실행을 방해하지 않습니다. 모든 컨트롤러 노드가 오프라인인 경우에도 쿼리 실행은 영향을 받지 않습니다. 모든 컨트롤러 노드가 오프라인이면 클러스터의 상태는 마지막 리더가 다운되었을 때 그대로 유지됩니다. 새 리더가 온라인 상태가 되면 클러스터는 재조정 활동을 재개하고 새 테이블 또는 세그먼트를 수락할 수 있습니다.
Controller REST interface
컨트롤러는 모든 논리적 저장소 리소스(서버, 브로커, 테이블 및 세그먼트)에서 CRUD 작업을 수행하기 위한 REST 인터페이스를 제공합니다.
웹 기반 관리 도구에 대한 자세한 내용은 Pinot Data Explorer를 참조하십시오.
Broker
브로커의 책임은 주어진 쿼리를 적절한 서버 인스턴스로 라우팅하는 것입니다. 브로커는 모든 서버의 응답을 수집하여 최종 결과로 병합한 다음 요청 클라이언트로 다시 보냅니다. 브로커는 SQL 쿼리를 수락하고 응답을 JSON 형식으로 반환하는 HTTP 끝점을 제공합니다.
브로커가 시작하려면 세 가지 핵심 사항이 필요합니다.
- 클러스터 이름
- Zoopeeper 주소
- 브로커 인스턴스 이름
처음에 브로커는 Helix 참가자로 등록하고 다른 Helix 에이전트의 알림을 기다립니다. 브로커는 구성 변경 외에도 테이블 생성, 로드되는 새 세그먼트 또는 서버 시작 또는 중단에 대한 이러한 알림을 처리합니다.
Service Discovery/Routing Table
알림의 종류와 관계없이 브로커의 주요 책임은 쿼리 라우팅 테이블을 유지 관리하는 것입니다. 쿼리 라우팅 테이블은 단순히 세그먼트와 세그먼트가 상주하는 서버 간의 매핑입니다. 일반적으로 세그먼트는 둘 이상의 서버에 상주합니다. 브로커는 테이블에 대해 구성된 라우팅 전략에 따라 여러 라우팅 테이블을 계산합니다. 기본 전략은 사용 가능한 모든 서버에서 쿼리 로드의 균형을 맞추는 것입니다.
Query Processing
모든 쿼리에 대해 클러스터의 브로커는 다음을 수행합니다.
- 테이블 구성에 정의된 라우팅 전략을 기반으로 쿼리에 대해 계산된 경로를 가져옵니다.
- 각 서버에서 쿼리할 세그먼트 목록을 계산합니다. 이에 대해 자세히 알아보려면 라우팅을 확인하십시오.
- Scatter-gather: 각 서버에 요청을 보내고 응답을 수집합니다.
- Merge: 각 서버에서 반환된 쿼리 결과를 병합합니다.
- 쿼리 결과를 클라이언트로 보냅니다.
Fault tolerance
브로커 인스턴스는 상한 없이 수평으로 확장됩니다. 대부분의 경우 브로커는 3개만 있으면 됩니다. 클라이언트에 반환되는 대부분의 쿼리 결과가 쿼리당 크기가 1MB 미만인 경우 동일한 인스턴스 컨테이너 내에서 브로커와 서버를 실행할 수 있습니다. 이렇게 하면 프로덕션에서 쿼리 성능에 대한 엄격한 SLA를 보장할 필요가 없는 사용 사례에 대한 클러스터 배포의 전체 공간이 줄어듭니다.
Server
서버는 세그먼트를 호스팅하고 쿼리 처리 중에 대부분의 어려운 작업을 수행합니다. 아키텍처는 실시간과 오프라인의 두 종류의 서버가 있음을 보여주지만 서버는 자신이 실시간 서버가 될지 오프라인 서버가 될지 실제로 알지 못합니다. 서버의 책임은 테이블 할당 전략에 따라 다릅니다.
Offline servers
오프라인 서버는 일반적으로 변경할 수 없는 세그먼트를 호스팅합니다. 이 경우 클러스터 외부에서 세그먼트가 생성되고 셸 기반 curl 요청을 통해 업로드됩니다. 복제 요소 및 세그먼트 할당 전략에 따라 컨트롤러는 세그먼트를 호스팅할 하나 이상의 서버를 선택합니다. 서버는 Helix를 통해 새 세그먼트에 대한 알림을 받습니다. 서버는 딥 스토어에서 세그먼트를 가져와 쿼리 요청을 처리할 준비가 되기 전에 로드합니다. 이 시점에서 클러스터의 브로커는 사용 가능한 새 세그먼트를 감지하고 이를 쿼리 응답에 포함하기 시작합니다.
Online servers
실시간 서버는 오프라인 서버와 다릅니다. 실시간 서버 노드는 Kafka와 같은 스트리밍 소스에서 데이터를 수집하고 인덱스 세그먼트를 메모리 내에서 생성합니다(세그먼트를 주기적으로 디스크로 플러시). 인 메모리 세그먼트는 소비 세그먼트(consuming segments)라고도 합니다. 이러한 소비 세그먼트는 완료 임계값(행 수, 시간 또는 세그먼트 크기 기반)에 따라 주기적으로 플러시됩니다. 이 시점에서 이를 완료된 세그먼트(completed segments)라고 합니다. 완료된 세그먼트는 오프라인 서버의 세그먼트와 유사합니다. 쿼리는 진행 중인(소비) 세그먼트와 완료된 세그먼트를 거칩니다.
Data ingestion overview
Pinot 내에서 논리적 테이블은 오프라인 또는 실시간의 두 가지 유형의 물리적 테이블 중 하나로 모델링됩니다. 두 가지 유형의 테이블이 있는 이유는 각각 다른 상태 모델을 따르기 때문입니다.
실시간 및 오프라인 테이블은 인덱싱을 위한 다양한 구성 옵션을 제공하며 실시간의 경우 스트림 데이터 원본(예: Kafka)에 대한 커넥터 속성을 제공합니다. 또한 테이블 유형을 통해 사용자는 실시간 및 오프라인 서버 노드에 대해 서로 다른 컨테이너를 사용할 수 있습니다. 예를 들어, 오프라인 서버는 큰 저장 용량을 가진 가상 머신을 사용할 수 있고, 실시간 서버는 높은 시스템 메모리 및/또는 더 많은 CPU 코어를 필요할 수 있습니다.
두 가지 유형의 테이블도 서로 다르게 확장됩니다.
- 실시간 테이블은 보존 기간이 더 짧고 수집 속도에 따라 쿼리 성능을 확장합니다.
- 오프라인 테이블은 저장된 데이터의 크기에 따라 보존 및 확장 성능이 더 큽니다.
워크로드에 대해 다양한 유형의 테이블을 구성할 때 염두에 두어야 할 몇 가지 사항이 있습니다. 동일한 원본에서 데이터를 수집할 때 실시간 및 오프라인 쿼리에 대해 다르게 구성된 동일한 데이터를 수집하는 두 개의 테이블이 있을 수 있습니다. 두 테이블의 데이터가 동일하더라도 요구 사항에 따라 쿼리에 따라 성능이 다르게 조정됩니다. 이 시나리오에서 실시간 및 오프라인 테이블은 동일한 스키마를 공유해야 합니다.
Batch data flow
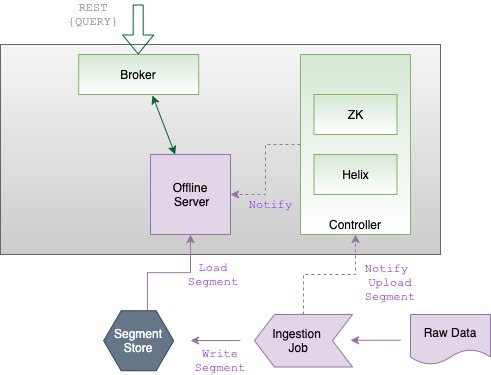
배치 모드에서 Pinot는 수집 작업을 통해 데이터를 수집합니다. 수집 작업은 raw data 소스(예: CSV 파일)를 세그먼트로 변환합니다. 가져온 데이터에 대한 세그먼트가 생성되면 수집 작업은 세그먼트를 클러스터의 세그먼트 저장소(딥 저장소라고도 함)에 저장하고 컨트롤러에 알립니다. 컨트롤러는 알림을 처리하여 컨트롤러의 Helix 에이전트가 Zookeeper의 이상적인 상태 구성을 업데이트합니다. 그런 다음 Helix는 사용 가능한 새 세그먼트가 있음을 오프라인 서버에 알립니다. 컨트롤러의 알림에 대한 응답으로 오프라인 서버는 새로 생성된 세그먼트를 클러스터의 세그먼트 저장소에서 직접 다운로드합니다. Helix에서 상태 변경을 감시하는 클러스터의 브로커는 새 세그먼트를 감지하고 쿼리할 세그먼트 목록(세그먼트-서버 라우팅 테이블)에 추가합니다.
Real-time data flow
테이블 생성 시 컨트롤러는 소비 세그먼트에 대해 Zookeeper에 새 항목을 생성합니다. Helix는 새 세그먼트를 인식하고 스트리밍 소스에서 데이터 소비를 시작하는 실시간 서버에 알립니다. 변경 사항을 감시하는 브로커는 새 세그먼트를 감지하고 쿼리할 세그먼트 목록(세그먼트-서버 라우팅 테이블)에 추가합니다.
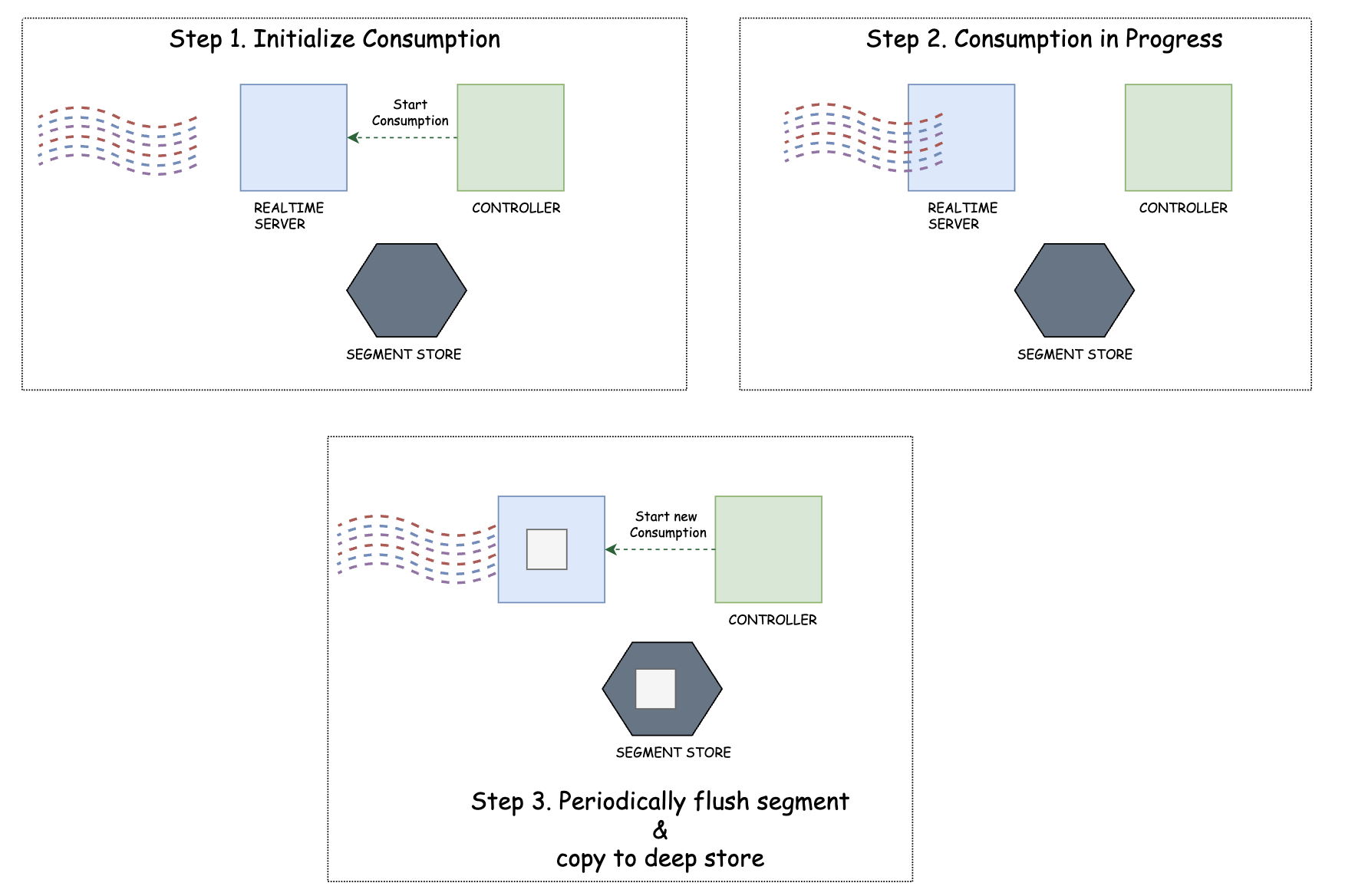
세그먼트가 완료(즉, 가득 찼을 때)될 때마다 실시간 서버는 모든 복제본을 확인하고 세그먼트를 커밋할 승자를 선택하는 컨트롤러에 알립니다. 승자는 세그먼트를 커밋하고 클러스터의 세그먼트 저장소에 업로드하여 세그먼트 상태를 "소비"에서 "온라인"으로 업데이트합니다. 그런 다음 컨트롤러는 "소비" 상태에서 새 세그먼트를 준비합니다.
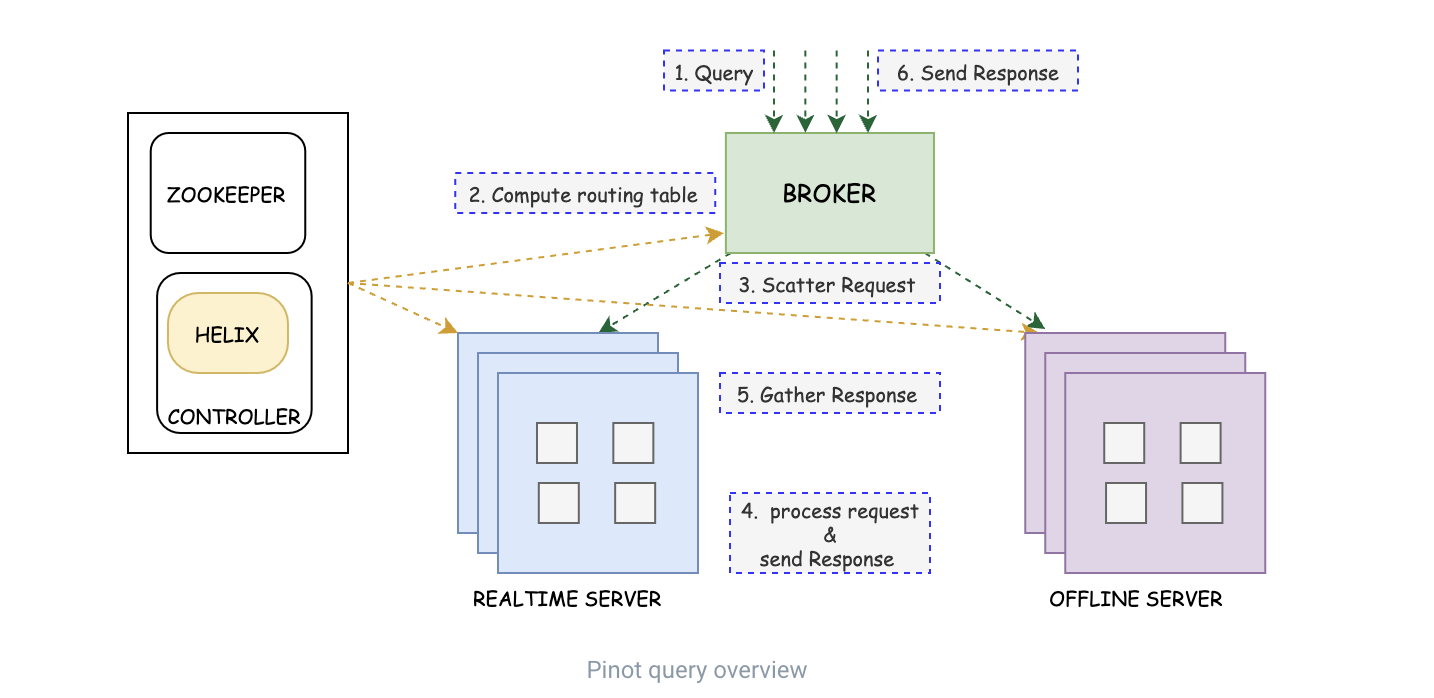
Query overview
쿼리는 실시간 서버와 오프라인 서버 간에 요청을 분산시키는 세그먼트 대 서버 라우팅 테이블에 대해 요청을 확인하는 브로커에 의해 수신됩니다. 그런 다음 두 테이블은 쿼리된 데이터를 필터링하고 집계하여 요청을 처리한 다음 브로커로 다시 반환합니다. 마지막으로 브로커는 쿼리 응답의 모든 부분을 함께 수집하고 결과로 클라이언트에 다시 응답합니다.
'개발 > DB' 카테고리의 다른 글
| [Apache Pinot #1] Apache Pinot 소개 (0) | 2023.04.16 |
|---|---|
| Local Cache에 대하여 (Spring Cache, Caffeine/Ehcache, Redis Client-side caching..) (0) | 2022.09.01 |
| Index / Clustered Index vs NonClustered Index (0) | 2022.08.24 |
| SQL (RDBMS)과 NoSQL, ACID와 BASE (0) | 2022.08.11 |
| CAP 정리와 PACELC 정리 (0) | 2022.08.10 |


댓글