본 포스트는 조나단바이에르, 쿠버네티스 기초다지기 3/e (에이콘)을 참고하여 정리하였습니다.
4장에서 다루는 내용
- Deployment
- Job
- DemonSet
쿠버네티스는 클러스터가 원하는 상태를 유지합니다. 이러한 상태를 운영자는 Deployment를 사용해 정의하고, 조정된 비율로 micro-service와 같은 stateless 서비스를 변경합니다.
Deployment
공식 문서: https://kubernetes.io/ko/docs/concepts/workloads/controllers/deployment/
디플로이먼트
디플로이먼트(Deployment) 는 파드파드는 클러스터에서 실행 중인 컨테이너의 집합을 나타낸다. 와 레플리카셋(ReplicaSet)레플리카셋은 지정된 수의 파드 레플리카가 동시에 실행이 되도록 보장한다
kubernetes.io
Deployment에 대해서 간단하게 소개해드리겠습니다.
Kubernetes는 클러스터가 원하는 상태를 유지할 수 있게 합니다. 이 '원하는 상태(Desire state)'를 Deployment에서 정의하며 현재 상태에서 원하는 상태로 비율을 조정하며 변경합니다. 이와 더불어 선언적 정의를 사용하여 Pod와 Replicaset을 업데이트해서 애플리케이션 rollout을 일시 중지하거나 다시 시작할 수 있으며, 과거 배포 이력을 유지해 사용자가 이전버전으로 쉽게 rollback할 수도 있습니다.
Deployment가 어떻게 쓰이는지 구체적으로 알아보겠습니다.
Use-case
- ReplicaSet을 rollout할 Deployment를 생성
- Deployment의 PodTemplateSpec을 업데이트해서 Pod의 새로운 상태를 선언
- Deployment의 현재 상태가 안정적이지 않다면, 이전 버전의 Deployment로 rollback
- 클러스터의 워크로드에 맞게 Scale-Up
- Deployment 일시중지로 PodTemplateSpec에 여러 수정사항을 적용하고, 새로운 rollout 시작 재개
- rollout이 막혀있는지를 나타내는 Deployment 상태 이용
- 필요없는 ReplicaSet 정리
node-js-deploy.yaml파일을 만들어 예를 들어보겠습니다.
apiVersion: apps/v1 //책: apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: node-js-deploy
labels:
name: node-js-deploy
spec:
replicas: 1
selector: //책에 없는
matchLabels: //apps/v1에
name: node-js-deploy //추가된 부분
template:
metadata:
labels:
name: node-js-deploy
spec:
containers:
- name: node-js-deploy
image: jonbaier/pod-scaling:0.1
ports:
- containerPort: 80
본 예시를 통해 Deployment객체를 변경하고, 업데이트해 쿠버네티스가 Pod와 ReplicaSet을 업데이트하도록 관리할 수 있음을 알 수 있습니다. 자세한 설명은 다음과 같습니다.
- .metadata.name 필드에 따라 node-js-deploy 이름으로 디플로이먼트가 생성됩니다.
- .spec.replicas 필드에 따라 디플로이먼트는 1개의 Replica Pod가 생성됩니다.
- .spec.selector 필드는 디플로이먼트가 관리할 파드를 찾는 방법을 정의합니다. 위 예시에서는 간단하게 파드 템플릿에 정의된 레이블(app: node-js-deploy)을 선택합니다.
- template 필드에는 다음 하위 필드가 포함되어 있습니다.
- Pod는 .metadata.labels 필드를 사용해서 app: node-js-deploy 라는 레이블을 붙입니다.
- .spec 필드는 파드가 도커 허브의 jonbaier/pod-scaling 0.1버전 이미지를 실행하는 컨테이너 1개를 실행하는 것을 나타냅니다.
- 컨테이너 1개를 생성하고, .spec.containers[0].name 필드를 사용해서 node-js-deploy 이름을 붙입니다.
- .spec.containers[0].ports[0].containerPort를 80번 port로 지정해 트래픽을 받게 구성했습니다.
작성한 Deployment를 생성하려면 아래의 명령어를 입력합니다.
kubectl create -f node-js-deploy.yaml
Deployment가 성공적으로 생성되었는지 확인하려면 아래의 명령어를 실행하면 됩니다.
kubectl get deployments
만약 rollout 상태를 확인하고 싶다면, 아래와 같은 명령어를 실행하면 됩니다. 참고로 rollout 상태는 나중에 deployment를 업데이트 할때 유용하므로 알아놓으면 좋을 것 같습니다.
kubectl rollout status deployment/node-js-deploy
이번에는 Service를 만들어보겠습니다. 먼저 node-js-deploy-service.yaml이라는 파일을 생성하고, 아래와 같이 작성해줍니다.
apiVersion: v1
kind: Service
metadata:
name: node-js-deploy
labels:
app: node-js-deploy
spec:
type: LoadBalancer
ports:
- port: 80
sessionAffinity: ClientIP
selector:
app: node-js-deploy
이제 kubectl node-js-deploy-service.yaml을 사용해 Service를 생성하면 이 namespace에 속한 pod의 내부에서 서비스 이름이나 서비스 IP를 통해 Deployment Pod에 접근할 수 있습니다. 부여받은 <ExternalIP>:80로 접속하면 아래와 같은 화면을 볼 수 있습니다.

Scaling
scale-up을 하려면 다음처럼 deployment 이름을 사용해 새로운 레플리카 수를 지정하면 됩니다.
kubectl scale deployment node-js-deploy --replicas 3
kubectl get pods라는 명령어를 실행하면 아래와 같이 replica 수가 3개인 것을 확인할 수 있습니다.

Kubernetes에서는 CPU 사용률을 기준으로 pod의 수를 오토스케일링 해주는 기능도 있습니다. 이를 HPA(Horizontal Pod Autoscaling)이라고 부르는데, 자세한 내용은 Kubernetes 공식문서: HPA를 참고하시면 됩니다.
Horizontal Pod Autoscaler
Horizontal Pod Autoscaler는 CPU 사용량 (또는 사용자 정의 메트릭, 아니면 다른 애플리케이션 지원 메트릭)을 관찰하여 레플리케이션 컨트롤러(ReplicationController), 디플로이먼트(Deployment), 레플리카셋(Rep
kubernetes.io
본 node-js-deploy 예제를 오토스케일링하는 커맨드는 다음과 같습니다. 오토스케일링을 하려면 Pod의 최소값과 최댓값을 설정해야 합니다.
kubectl autoscale deployment node-js-deploy --min=25 --max=30 --cpu-percent=75Update와 Rollout
디플로이먼트를 사용하면 여러가지 방식으로 업데이트를 할 수 있습니다.
아래는 위에서 배포한 node-js-deploy 파드의 도커이미지 버전을 변경하는 예제입니다. 해당 파드의 이미지를 알기 위해 kubectl describe pod/node-js-deploy-dcf5f6467-86ptw | grep Image: 명령어를 입력하면 아래와 같은 결과를 확인할 수 있습니다.

현재 실행중인 디플로이먼트의 이미지버전을 알았으니 업데이트를 해보겠습니다.
먼저 명령어를 실행하는 방법입니다. kubectl set 커맨드를 사용하면 수작업으로 재배포할 필요없이 디플로이먼트 설정을 변경할 수 있습니다.
kubectl set image deployment/node-js-deploy node-js-deploy=jonbaier/pod-scaling:0.2
제대로 진행이 된다면 "deployment.extensions/node-js-deploy image updated" 라는 문장이 화면에 출력될 것입니다. 다음으로 rollout status 커맨드를 사용해 상태를 다시 한 번 확인할 수 있습니다.

다음으로는 kubectl edit 커맨드로 편집기 창에서 디플로이먼트를 직접 편집해 변경하는 방법입니다. image를 찾아 jonbaier/pod-scaling:0.2로 변경하면 됩니다.
여기서 중요한 점은 쿠버네티스는 새로운 버전의 레플리카셋을 생성하면서 조용히 업데이트합니다. 이 파드가 문제없이 Online이 되면 기존 버전 중 하나를 중단합니다. 그리고 새 파드만 남을 때 까지 새 버전을 scale-out하고 기존 버전을 scale-down하는 동작을 반복합니다. 아래의 그림에서 node-js-deploy-598c659594는 이미지 버전을 업데이트하며 새롭게 생성된 파드의 레플리카셋입니다. deployment의 수명주기의 경우 책 p208를 참고하면 더 자세히 알 수 있습니다.

History와 Rollback
Kubernetes는 디플로이먼트 이력을 추적할 수 있게 History를 제공합니다. 직접 히스토리를 보기 전에 kubectl set image deployment/node-js-deploy node-js-deploy=jonbaier/pod-scaling:0.3를 입력해 버전을 0.3으로 업데이트하겠습니다. 이후 히스토리를 살펴보면 다음과 같이 출력됩니다.

책에서는 CHANGE-CAUSE까지 나오는데 제 환경에서는 나오지 않네요ㅠㅠ 이유를 아시는 분 있다면 알려주시면 감사하겠습니다. 어쨌든 REVISION을 통해 버전 업데이트가 일어났다는 것을 확인할 수 있습니다. rollout 커맨드의 서브커맨드로 다음과 같은 것들도 있습니다.
- pause: 진행 중인 rollout커맨드를 일시중지 할 수 있습니다.
- resume: rollout을 계속하려고 할 때 사용합니다.
- undo/history: 뭔가 문제가 발생했을 경우 유용합니다.
아직 docker hub에 올라오지 않은 파드 버전인 42버전으로 업데이트를 시도해 undo를 사용해보겠습니다. 아래와 같이 set 명령어를 실행시키고, rollout status 명령어를 통해 파드의 상태를 확인합니다.

25개의 파드 중 13개를 업데이트 한 뒤 배포가 일시중지 되었으며, 전체 애플리케이션이 오프라인 상태가 되는 것을 방지하기 위해 쿠버네티스가 배포를 중단한 것을 확인할 수 있습니다. get pods 명령어를 실행하여 파드의 상태를 보면 ImagePullBackOff 오류가 발생하고 있다는 것을 확인할 수 있습니다.
이러한 rollout이 실패하는 상황이 발생할 때마다 rollout undo 커맨드를 이용해 이전버전으로 쉽게 롤백할 수 있습니다. 이후 rollout status 와 rollout history 커맨드를 실행하여 성공적으로 rollout이 되고 복구된 이력을 확인할 수 있습니다.
특정 버전으로 되돌리고 싶다면 --to-revision 플래그를 지정하면 됩니다.
AutoScaling
디플로이먼트를 지원하는 스케일링 방식 중 HPA가 있다는 것을 위에서 언급했습니다. 이를 사용하면 CPU 사용률에 따라 파드 수를 조정해 클러스터 가동률을 관리할 수 있습니다. HPA는 데몬셋을 제외한 세가지 오브젝트인 디플로이먼트 (권장), 레플리카셋, 레플리케이션 컨트롤러 (비권장)을 스케일링 할 수 있습니다.
HPA는 제어 루프로 구현되며 기본 값이 30초인 --horizontal-pod-autoscaler-sync-period 값을 기준으로 동기화 기간을 조정할 수 있습니다. 직접 부하를 넣어 autoscaling을 해볼 것인데, 그 이전에 기존에 만들었던 node-js-deploy.yaml 파일을 조금 수정하도록 하겠습니다.
...
spec:
containers:
- name: node-js-deploy
image: jonbaier/pod-scaling:0.1
ports:
- containerPort: 80
resources:
requests:
cpu: 200m
limits:
cpu: 500m
기존의 파일에서 .spec.containers.resources 필드를 추가하여 요구 cpu량과 최대 증대 cpu량을 지정해 주었습니다.
이후, node-js-deploy-hpa.yaml 파일을 생성해 HPA를 만들어 보겠습니다. CPU 기준값을 10%로 낮추고 파드의 최솟값과 최댓값을 3과 6으로 변경했습니다.
apiVersion: autoscaling/v2beta2 #책과 다름
kind: HorizontalPodAutoscaler
metadata:
name: node-js-deploy
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: node-js-deploy
minReplicas: 3
maxReplicas: 6
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 10
이후 kubectl create -f node-js-deploy-hpa.yaml 커맨드를 사용해 HPA를 생성하고 kubectl get hpa 커맨드로 hpa가 떠있는지 확인할 수 있다.

이제 autoscaler를 트리거하기 위해 부하를 주기위해 테스트를 진행해보겠습니다. 먼저 boomload-deploy.yaml 파일을 만들고, kubectl create -f boomload-deploy.yaml 커맨드를 실행해 디플로이먼트를 생성합니다. 이후 kubectl get hpa 커맨드와 kubectl get deploy 커맨드를 번갈아 사용해 HPA를 모니터링 하면, 몇분뒤 10%이상으로 부하가 올라가는 것으로 보이고 파드 수가 최대 6개 까지 올라가는 것을 확인할 수 있습니다.
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: boomload-deply
spec:
replicas: 1
template:
metadata:
labels:
app: loadgenerator-deploy
spec:
containers:
- image: williamyeh/boom
name: boom-deploy
command: ["/bin/sh", "-c"]
args: ["while true ; do boom http://node-js-deploy/ -c 100 -n 500 ; sleep ; done"]
아래의 사진은 레플리카셋이 부하에 의해 4개가 된 것을 확인할 수 있습니다. 만약 kubectl delete deploy boomload-deploy 명령어를 실행하고, 몇 분 뒤 CPU 부하가 0%가 되면 레플리카 수가 줄어드는 것을 확인할 수 있습니다.
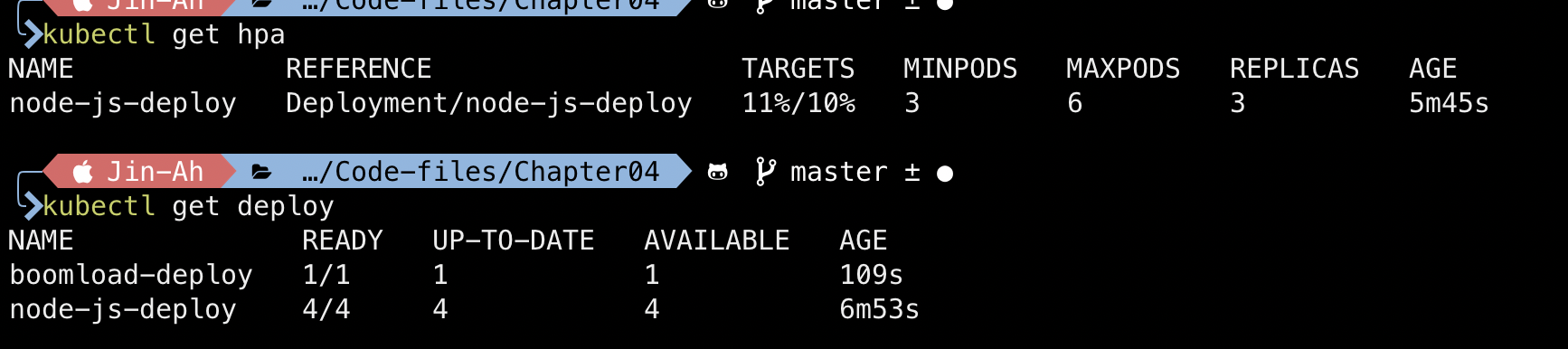
직접 HPA를 더 해보고 싶다면 HPA 연습을 따라해보시면 될 것 같습니다.다음은 잡에 대해서 알아보겠습니다.
Horizontal Pod Autoscaler 연습
Horizontal Pod Autoscaler는 CPU 사용량(또는 베타 지원의 다른 애플리케이션 지원 메트릭)을 관찰하여 레플리케이션 컨트롤러, 디플로이먼트, 레플리카셋(ReplicaSet) 또는 스테이트풀셋(StatefulSet)의 파드
kubernetes.io
Job
Deployment는 실행 시간이 긴 애플리케이션이 항상 실행되어야할 때 좋은 방법이라면, 수명이 짧고 한번만 실행하면 되는 태스크나 정기적인 예약이 필요한 태스크는 Deployment에 적합하지 않을 수 있습니다. 둘다 태스크가 종료 될 때까지 실행해야하고, 정기적인 태스크의 경우 다음 주기에 맞춰 다시 시작해야합니다.
이런 유형의 워크로드를 처리하기 위해 Job 등의 배치 API가 쿠버네티스에 추가되었습니다. 1~n개의 Pod를 생성하고, 모든 Pod는 성공적인 종료와 함께 완료가 됩니다. 추가로 설정의 restartPolicy 필드를 Never로 설정하면 파드를 재시작하지 않고 실패한 채로 두며, OnFailure로 설정하면 파드가 성공적으로 완료되지 않았을 때 재시작합니다.
다음 longtask.yaml 예제에서는 OnFailure로 설정하여 작성하고, kubectl create -f longtask.yaml 를 실행해 Job을 띄웁니다.
apiVersion: batch/v1
kind: Job
metadata:
name: long-task
spec:
template:
metadata:
name: long-task
spec:
containers:
- name: long-task
image: docker/whalesay
command: ["cowsay", "Finishing that task in a jiffy"]
restartPolicy: OnFailure
이제 long-task 잡이 성공적으로 생성되면 kubectl describe jobs/long-task 커맨드를 입력해서 아래의 그림과 같이 SuccessfulCreate 가 떠있는지 확인하면 됩니다. 이때 Created pod: long-task-hgncr 이라고 적혀있는 정보를 바탕으로 UI를 통해 제대로 Job이 실행되었는지 확인할 수 있습니다.

kubectl logs $pods 라고 명령어를 입력해봅시다. 이때 $pods에 들어갈 부분은 위에서 출력된 정보인 "Created pod: long-task-hgncr"의 노란색 부분입니다. 입력하면 다음과 같은 로그를 볼 수 있게 됩니다.

Parallel-Job (병렬 잡)
병렬잡을 사용하면 진행중인 큐에서 작업을 가져오거나 서로 의존하지 않는 일련의 작업을 간단하게 실행할 수 있습니다. 큐에서 잡을 가져오는 경우, 애플리캐이션 의존성과 태스크 처리 방식 및 다음 수행작업을 결정하는 로직이 있어야합니다. 즉, 쿠버네티스는 단순히 Job을 수행하기만 한다는 것을 명심해야 합니다. 더 자세한 내용은 Kubernetes 공식문서: 병렬 잡 를 참고하시면 될 것 같습니다.
잡 - 실행부터 완료까지
잡에서 하나 이상의 파드를 생성하고 지정된 수의 파드가 성공적으로 종료되도록 한다. 파드가 성공적으로 완료되면, 성공적으로 완료된 잡을 추적한다. 지정된 수의 성공 완료에 도달하면, 작�
kubernetes.io
DemonSet
DemonSet은 모든(또는 일부) 노드가 파드의 사본을 실행하도록 합니다. 만약 노드가 클러스터에 추가되면 파드도 추가되며, 노드가 클러스터에서 제거되면 해당 파드는 가비지(garbage)로 수집됩니다. 또한 DemonSet을 삭제하면 DemonSet이 생성한 파드들이 정리됩니다.
다음은 DemonSet의 대표적인 usage입니다.
- 모든 노드에서 클러스터 스토리지 데몬 실행
- 모든 노드에서 로그 수집 데몬 실행
- 모든 노드에서 노드 모니터링 데몬 실행
이 DemonSet을 이용하여 클러스터의 모든 노드나 지정한 일부 노드에서만 실행할 파드를 간단히 정의할 수 있습니다. 또한 모니터링, 로깅 에이전트, 보안 에이전트 및 파일 시스템 데몬과 같은 여러 운영 관련 작업에도 매우 유용합니다.
yaml파일로 DemonSet을 정의한 내용을 살펴보겠습니다.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
#// this toleration is to have the daemonset runnable on master nodes
#// remove it if your masters can't run pods
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers노드 선택
DemonSet은 일부 노드에서만 실행되도록 스케줄링이 가능하고, 이를 위해 nodeSelector를 사용합니다. nodeSelector는 특정 레이블과 메타데이터를 찾아 파드가 실행될 노드를 제한 할 수 있습니다.
이때 각 노드 레이블의 키/값 쌍을 단순 비교하며 고유의 레이블을 추가하거나 기본으로 할당된 레이블을 사용할 수 있습니다.
| 기본 노드 레이블 | 설명 |
| kubenetes.io/hostname | 기반 인스턴스나 머신의 호스트 이름을 나타낸다 |
| beta.kubernetes.io/os | Go 언어로 얻은 기반 OS를 나타낸다 |
| beta.kubernetes.io/arch | Go 언어로 얻은 기반 프로세서 아키텍처를 나타낸다 |
| beta.kubernetes.io/instance-type | 기반 클라우드 프로바이더의 인스턴스 유형이다 (클라우드만 지원) |
| beta.kubernetes.io/region | 기반 클라우드 프로바이더의 리전이다(클라우드만 지원) |
| fail-domain.beta.kubernetes.io/zone | 기반 클라우드 프로바이더의 fault-tolerance 영역이다(클라우드만 지원) |
nodeSelector를 정의하게 되면 레이블이 일치하는 노드에 파드를 실행하고 후보가 없다면 실패하게 됩니다.
https://kubernetes.io/ko/docs/concepts/workloads/controllers/daemonset/
데몬셋
데몬셋 은 모든(또는 일부) 노드가 파드의 사본을 실행하도록 한다. 노드가 클러스터에 추가되면 파드도 추가된다. 노드가 클러스터에서 제거되면 해당 파드는 가비지(garbage)로 수집된다. 데몬��
kubernetes.io
'개발 > Docker & Kubernetes' 카테고리의 다른 글
| [k8s study] 15. 쿠버네티스 인프라 관리 (0) | 2020.11.27 |
|---|---|
| [k8s study] 8. 모니터링과 로깅 (0) | 2020.10.06 |
| [k8s study] 1장. 쿠버네티스 소개 (0) | 2020.08.06 |
| [k8s study] 쿠버네티스 기초다지기 3/e (0) | 2020.08.06 |
| 쿠버네티스 (Kubernetes) 한번에 정리하기 (0) | 2020.08.03 |




댓글