CNN은 필터링 기법을 인공신경망에 적용함으로써 이미지를 효과적으로 처리하는 것을 목표로한다. 기본 개념은 행렬로 표현된 필터의 각 요소가 데이터 처리에 적합하도록 학습되게 하자는 것이다.
머신러닝을 공부하면서
- 필터라는 걸 통해서 특징을 추출하는 것은 알겠는데, 그래서 어떻게 기계가 그림을 인지한다는 거지?
- 필터의 원리는 뭘까..? 수학 식으로 이차저차해서 뭔가 결과가 나오는 것은 알겠는데, 그래서 필터가 어떻게 특징을 추출해?
라는 생각을 해본 경험이 있습니다. 의문을 해결하기 위해 각종 원리를 찾아보았는데, 제 입장에서는 머릿속에 쉽게 들어오지 않았던 용어들과 식들로 인해 이해는 이해대로 안되고, 흥미는 흥미대로 잃는 경우가 많았었습니다.
그러다 조대협님의 블로그에서 해당 내용과 관련하여 쉽게 이해할 수 있었고, 이해했던 내용을 조금이나마 정리해놓고자 이 글을 작성하게 되었습니다. 갓대협님의 블로그에 CNN 기본 원리에 대해서 쉽고, 자세하게 정말 잘 설명되어 있기 때문에 제 블로그에서는 정말 요점에 대해서만 정리해놓겠습니다. (https://bcho.tistory.com/1149?category=555440)
딥러닝 - 초보자를 위한 컨볼루셔널 네트워크를 이용한 이미지 인식의 이해
딥러닝 - 컨볼루셔널 네트워크를 이용한 이미지 인식의 개념 조대협 (http://bcho.tistory.com) 이번 글에서는 딥러닝 중에서 이미지 인식에 많이 사용되는 컨볼루셔널 뉴럴 네트워크 (Convolutional neural n
bcho.tistory.com
CNN의 구조
먼저 일반적인 인공신경망(ANN)의 그림은 아래와 같이 fully-connected계층을 여러 층 쌓은 구조이다.
CNN은 기존의 ANN 구조 앞에, Convolutional Layer와 Polling Layer를 추가한 구조라고 생각하면 된다.
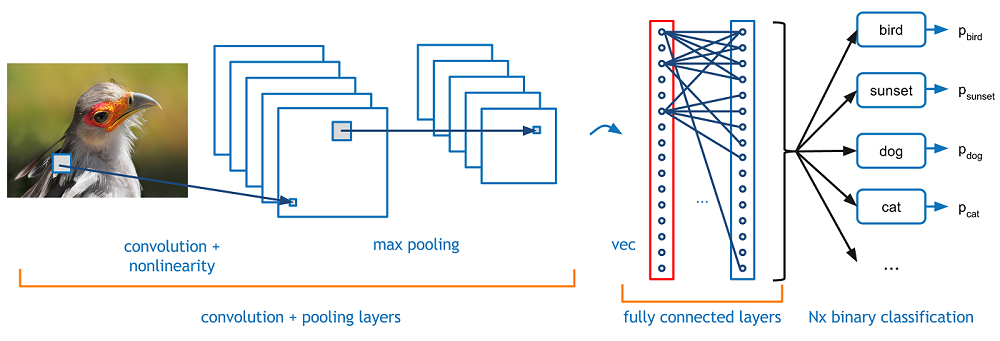
Convolutional Layer (합성곱 계층)
필터 (filter)
Filter를 통해 특징을 추출할 수 있고 이 추출한 특징을 Feature map이라고 한다. 참고로 필터는 데이터를 넣고 학습을 시키면 자동으로 학습데이터에서 학습을 통해 특징을 인식하고 필터를 만들어 낸다고 한다. 그리고 필터를 적용해 얻은 결과를 Feature Map이라고 한다.
Stride
필터를 원본이미지에 컨볼루션할 때, 얼마만큼의 간격으로 진행할지에 대한 값을 stride라고 한다.
Padding
필터를 적용할 때 결과값이 작아되는데, 이러한 현상을 막기위해 input계층 주위로 특정한 값(예를 들어, 0)으로 둘러쌓는 것을 Padding이라고 한다. 이를 통해 결과값이 작아지는 것을 막는 특징이 유실되는 것을 막고 오버피팅을 방지한다.
활성화 함수 (Activation Function)
필터를 통해 얻은 Feature map에 활성화 함수(Activation function)을 적용한다. 활성화 함수의 역할은 Feature map에 특징이 있으면 픽셀은 큰값, 특징이 없는 픽셀은 0에 가까운 값이 담겨있다. 이 값이 정량적인 값으로 나오기 때문에, 이 값을 특징이 "있다 없다"의 비선형 값으로 바꿔주는 과정이 필요한데, 이것이 바로 Activation Function이다.
다양한 활성화함수가 있는데 (https://reniew.github.io/12/ 참고), 보통 활성화함수로 ReLu 함수를 사용한다.
ReLu를 주로 사용하는 이유
뉴럴 네트워크에서는 신경망이 깊어질수록 학습이 어렵다는 문제점이 있다. 이를 보완하기 위해 Back propagation (역전파)라는 방법을 사용하는데, 이는 계산한 값을 재활용하여 다시 계산하는 것을 말한다. sigmoid함수의 경우 레이어가 깊어지면 역전파가 제대로 작동하지 않기 때문에(*값을 뒤에서 앞으로 전달할 때 희석되는 현상), ReLu를 사용한다.
선형함수가 아닌 비선형 함수를 사용하는 이유
비선형 함수를 사용하는 이유는 선형함수를 사용할 시 층을 깊게 하는 의미가 줄어들기 때문이다. 선형함수 f(x) = ax를 3층 네트워크로 쌓았다고 할 때 y(x) = f(f(f(x)))가 된다. 이는 사실 y(x) = cx와 같은데, c = a^3 이기 때문이다. 따라서 은닉층의 의미가 없어지기 때문에 층을 쌓는 것을 통해 더 좋은 결과같을 도출해내는 목적을 이루기 위해서는 비선형함수를 활성화함수로 선택해야 한다.
Polling Layer (풀링 계층)
컨볼루션 레이어를 통해 추출된 특징들은 필요에 따라 서브 샘플링(sub sampling)을 거친다. 추출된 모든 특징을 가지고 판단할 필요가 없기 때문인데, 해상도가 높은 사진을 보고 물체를 판달할 수 있지만 낮은 사진으로도 그사진이 어떤 내용인지 판단할 수 있다는 것과 같은 원리이다.
활성화 함수까지 거쳐 나온 Feature Map을 인위로 줄이는 작업을 서브 샘플링, 즉 풀링(Polling)이라고 한다. 풀링 방법은 다양한데 주로 max polling을 기반으로 구현되지만, average polling, L2-norm polling 등이 있다.
Max Polling (맥스 풀링)
Feature map을 M x N 사이즈로 조각내서, 그 국소 영역마다 가장 큰 값을 뽑아내는 방법이다. 이는 특징의 값이 큰 값이 다른 특징들을 대표한다라는 개념을 기반으로 하고 있다.
참고로 풀링은 액티베이션 함수 이후에 항상 적용되는 것이 아니라, 데이터의 크기를 줄이고 싶을 때 선택적으로 적용하는 것이다.
Fully Connected Layer
Convolution계층과 Polling계층을 통해 추출된 특징 값을 기존의 인공신경망에 넣어 분류를 해야한다. 이 Fully Connected Layer는 기존 인공 신경망의 구조라고 생각하면 된다. 이 계층을 지나면 Dropout 계층과 Softmax Function을 거쳐서 Output이 나오게 된다.
Dropout Layer (드롭아웃 계층)
드롭아웃은 오버피팅을 막기위한 방법으로 뉴럴 네트워크가 학습중일 때, 랜덤하게 뉴런을 꺼서 학습을 방해하는 기법이다. 이를 통해 모델이 학습용 데이터에 과적합(오버피팅)하는 현상을 막아준다.
Softmax 함수
sigmoid, LeRu와 같은 액티베이션 함수의 일종이다. sigmoid가 결과 값에 따라 1, 0과 같이 이산 분류하는 함수라면, Softmax는 여러개의 분류를 가질 수 있는 함수이다. 이 결과로는 다음과 같은 예시로 나올 수 있다.
카테고리가 자동차, 트럭, 비행기, 기차일 때 어떤 인풋데이터에 대해서
- 자동차일 확률은 0.7
- 트럭일 확률 0.2
- 비행기일 확률 0.03
- 기차일 확률 0.07
과 같이 표시가 된다. 이때 모든 카테고리 확률의 합은 1이되어야 한다.
'개발 > ML' 카테고리의 다른 글
| Machine Learning 개념 (0) | 2022.06.16 |
|---|---|
| Inception & Xception (0) | 2020.12.20 |
| 인공지능, 데이터 마이닝, 머신러닝, 딥러닝의 차이점 (0) | 2020.12.09 |



댓글