Overview
본 포스트는 Spark Release 3.0 공식 페이지의 Jira 티켓을 참고하여 작성하였습니다.
- Spark 3.0에서 향상된 기능은 Structed streaming, MLlib의 library, SQL, DataFrame의 API에도 영향을 미침
- 최적화와 관련된 다양한 것들이 추가
- Spark 3.0은 Spark 2.4보다 약 2배 빠름 (30TB 환경의 TCP-DS)
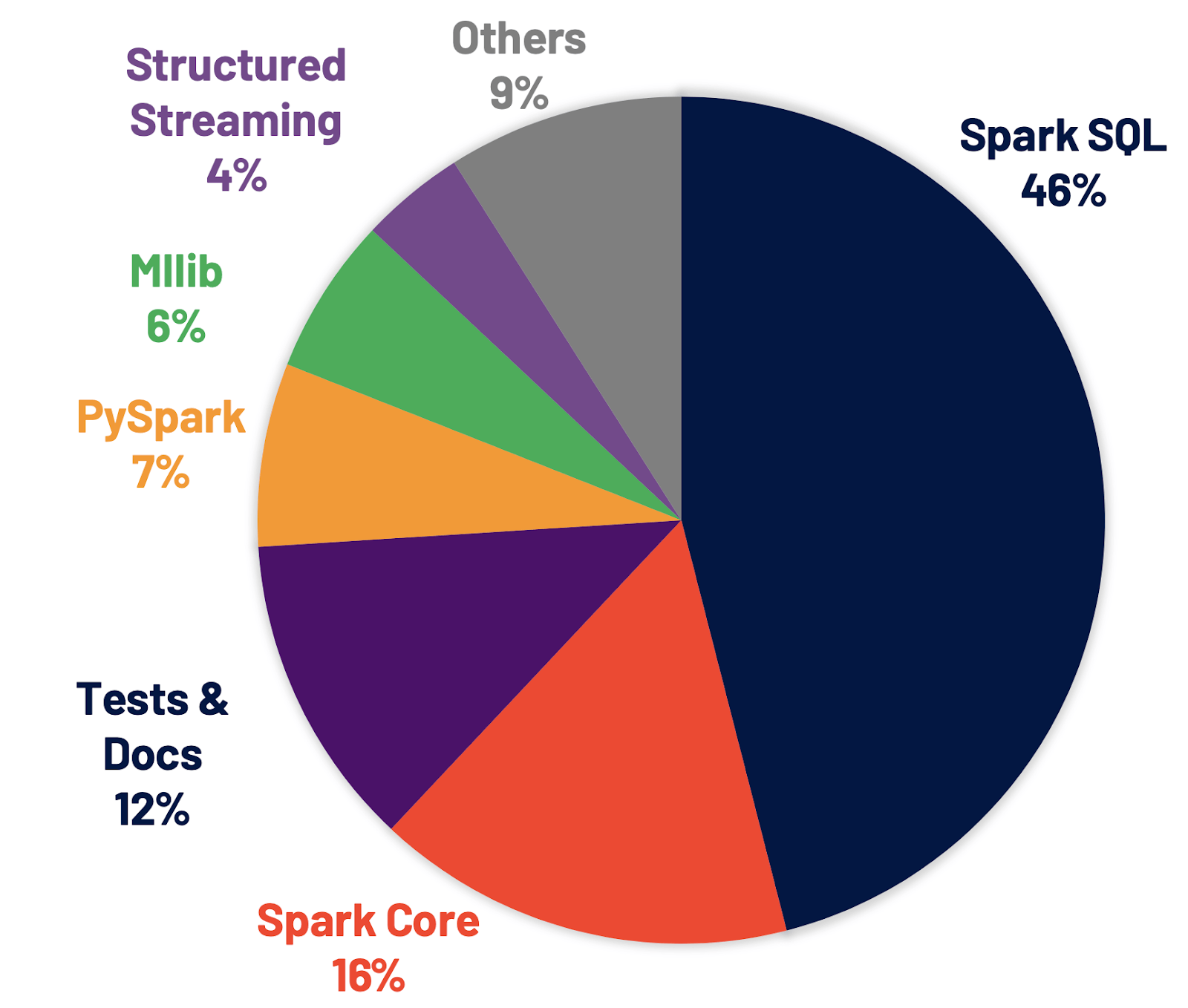
- Spark SQL: Release에서 가장 많이 변화, 해결된 티켓의 46%
- PySpark: 기능과 사용성이 개선
- Python의 타입 힌트와 새로운 padas UDF(User Defined Function) type를 포함하여 pandas의 UDF API를 재설계
- 더 나은 Python스러운 에러 핸들링이 포함
- Others
- JDK 11지원으로 JVM 자체의 성능 향상 (+GC) 기대
- Hadoop개선으로 S3에 접속할 때 S3A 등의 최신 conncetor를 사용 가능
- Scala 2.11 제거됨에 따라 backward compatibility를 고려X
- ORC 버전 업데이트
TCP-DS
빅데이터 시스템을 포함해 의사 결정 지원 솔루션 성능을 측정하기 위한 업계 표준 벤치마크
Supported version
- Spark runs on Java 8/11, Scala 2.12, Python 2.7+/3.4+ and R 3.1+.
- Java 8 prior to version 8u92 support is deprecatedas of Spark 3.0.0.
- Python 2 and Python 3 prior to version 3.6 support is deprecatedas of Spark 3.0.0.
- R prior to version 3.4 support is deprecatedas of Spark 3.0.0.
- For the Scala API, Spark 3.0.0 uses Scala 2.12. You will need to use a compatible Scala version (2.12.x).
- Remove Support for hadoop 2.6 (SPARK-25016)
Highlight Feature
- 2x performance improvement on TPC-DS over Spark 2.4 (TCP-DS에서 Spark 2.4보다 약 2배 빠름)
- Adaptive query execution (적응 쿼리 지원)
- Dynamic partition pruning (동적 파티션 정리)
- other optimizations (그 이외의 최적화 도입)
- ANSI SQL compliance (ANSI(표준) SQL 준수)
- Significant improvements in pandas APIs (Pandas API의 상당한 개선)
- Including Python type hints & additional pandas UDF(User Defined Functions) (python의 type 힌트와 pandas의 UDFs를 추가한 것을 포함)
- Better Python error handling, simplifying PySpark exceptions (Python error 핸들링 개선)
- New UI for structured streaming (structured streaming을 위한 새로운 UI)
- Up to 40x speedups for calling R UDFs (R UDF 호출시 최대 40배 속도 향상)
- Accelerator aware scheduler (Accelerator 키 인식 Scheduler)
- SQL reference documentation (SQL 참조 문서)
Improving the Spark SQL engine
- 패치의 46% 가량이 Spark SQL
- 퍼포먼스와 ANSI 호환성 모두 향상
- TCP-DS에서 Spark 2.4보다 약 2배 빠름

Adaptive Query Execution (AQE)[SPARK-31412]
Background
- 계획 초기에서 부정확하거나 누락된 통계, 잘못 추정된 비용으로 다른 Query를 계획해야하는 경우가 발생
- AQE는 이러한 상황에도runtime에 더 나은 실행계획을 생성(reoptimzing and adjusting)해 성능을 향상하고 튜닝을 단순화함
Spark Catalyst Optimizer History
- Spark 1.x: Rule-Based Optimizer
- Spark 2.x: Rule + Cost-Based Optimizer
- Spark 3.x: Rule + Cost + Runtime Based Optimizer (AQE)
Reoptimize가 되는 시기

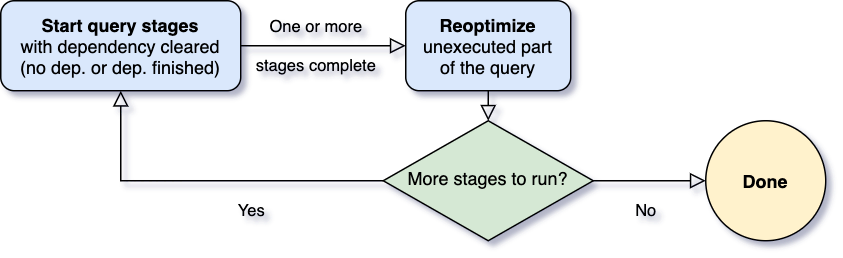
- Spark 연산자는 종종 piplined되고 병렬 프로세스가 실행
- shuffle, broadcast와 같은 동작을 수행하기 전 (Stage가 한차례 마무리되고 다음 Stage로 가기 전), Data pipline이 끊기고 실행을 멈춤 → 구체화(materialization)지점
- 중간 결과물을 구체화하고, 해당 Stage의 병렬처리가 완벽하게 끝나야 다음 스테이지 동작 →이 지점이 reoptimization을 할 기회
- 최적화는 통계치를 바탕으로 runtime에 진행
이번 Release에서는 세개의 주요 최적화 기능을 소개합니다.
three major adaptive optimizations
1. Dynamically coalescing shuffle partitions (동적 셔플 파티션 통합)
- 셔플은 비용이 높은 연산으로 쿼리 성능에 매우 큰 영향을 미침 → 적절한 수의 partition을 결정하는 것이 중요
- Too small shuffle partitions # : GC pressure; disk spilling; Slow down the query
- Too large shuffle partitions # : Inefficient I/O; scheduler pressure
(대부분은 처음에 파티션 수를 많이 잡아두고, 결과 통계치를 통해 인접한 직은 파티션들을 큰 파티션으로 합치면서 런타임 때 파티션 수를 조절)
ex) SELECT max(i) FROM tbl GROUP BY j (tbl is rather small so only two partitions before grouping)
Before
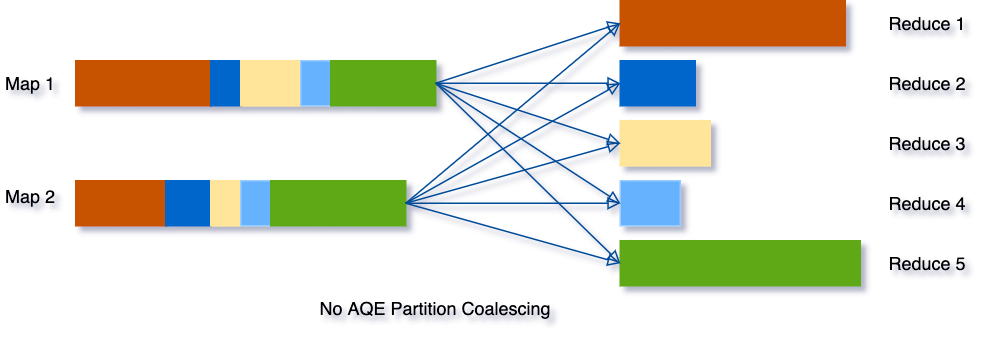
- AQE가 없으면 Spark는 최종 집계를 수행하기 위해 5개의 작업 실행
- 3개의 작은 파티션은 각각에 대해 별도의 작업을 시작하는 데 낭비
After AQE

- AQE가 reoptimization때 작은 파티션들을 하나로 합쳐주어, 5개의 작업이 3개의 작업으로 줄어듬 → 처리속도 증가
2. Dynamically switching join strategies (동적 전환 Join 전략)
- Spark는 여러가지 Join 전략 지원 (Broadcast hash join, Sort merge join..)
- AQE는 한차례 셔플이 끝나고 Reoptimization을 진행할 때,더 높은 성능을 내는 Join 전략이 있다면 runtime에 바꿔 최적화 진행
- Broadcast hash join: 조인할 대상 중 하나가 메모리에 잘 맞을 경우 일반적으로 가장 성능이 좋음
- 네트워크 트래픽을 줄이는 이점 (BroadCast hash join은 셔플 사용 X)
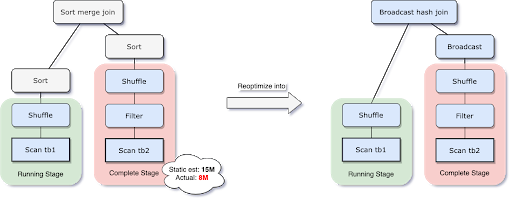
3. Dynamically optimizing skew joins (skew join을 동적으로 최적화)
skew: partition 하나에 데이터가 몰려있는 상황 → disk spill, oom
Before
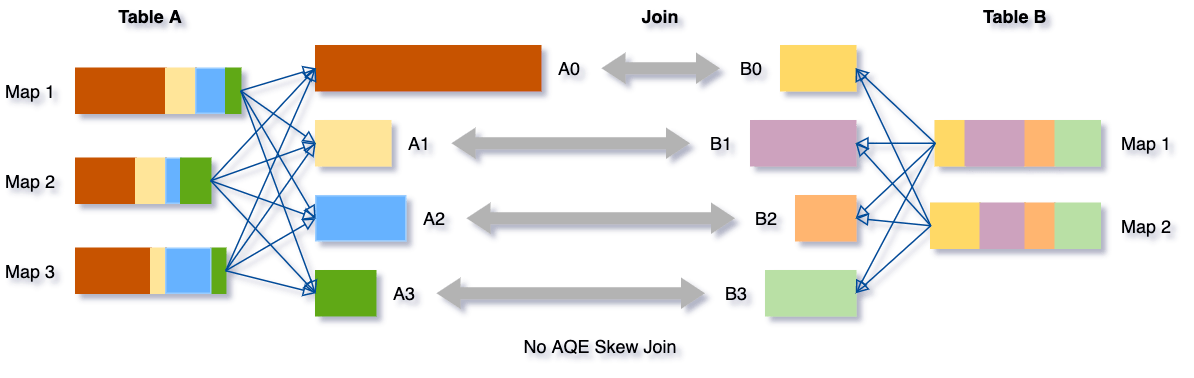
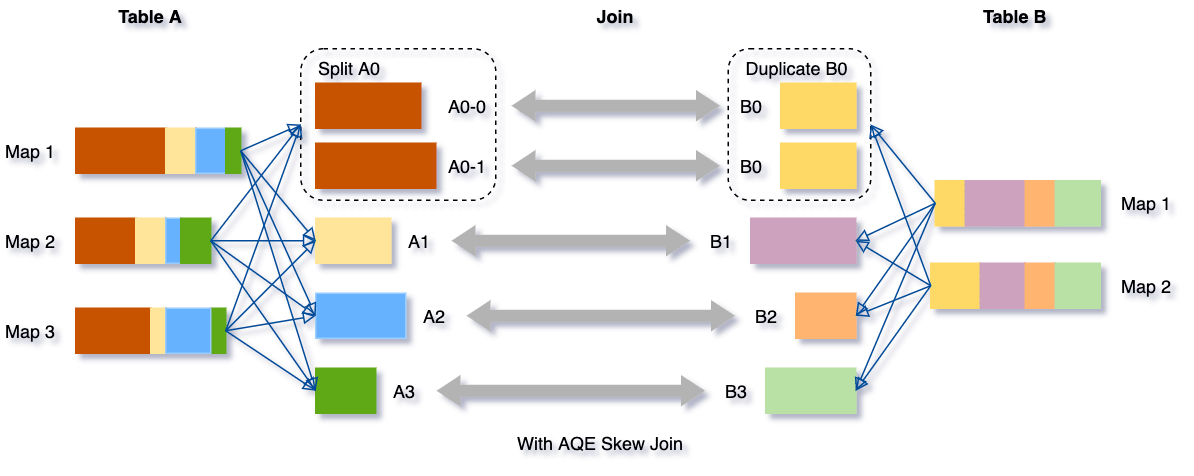
→ AQE 는 이러한 skew 데이터를 감지하고, skew 데이터를 더 작은 하위 파티션으로 나눔
After AQE
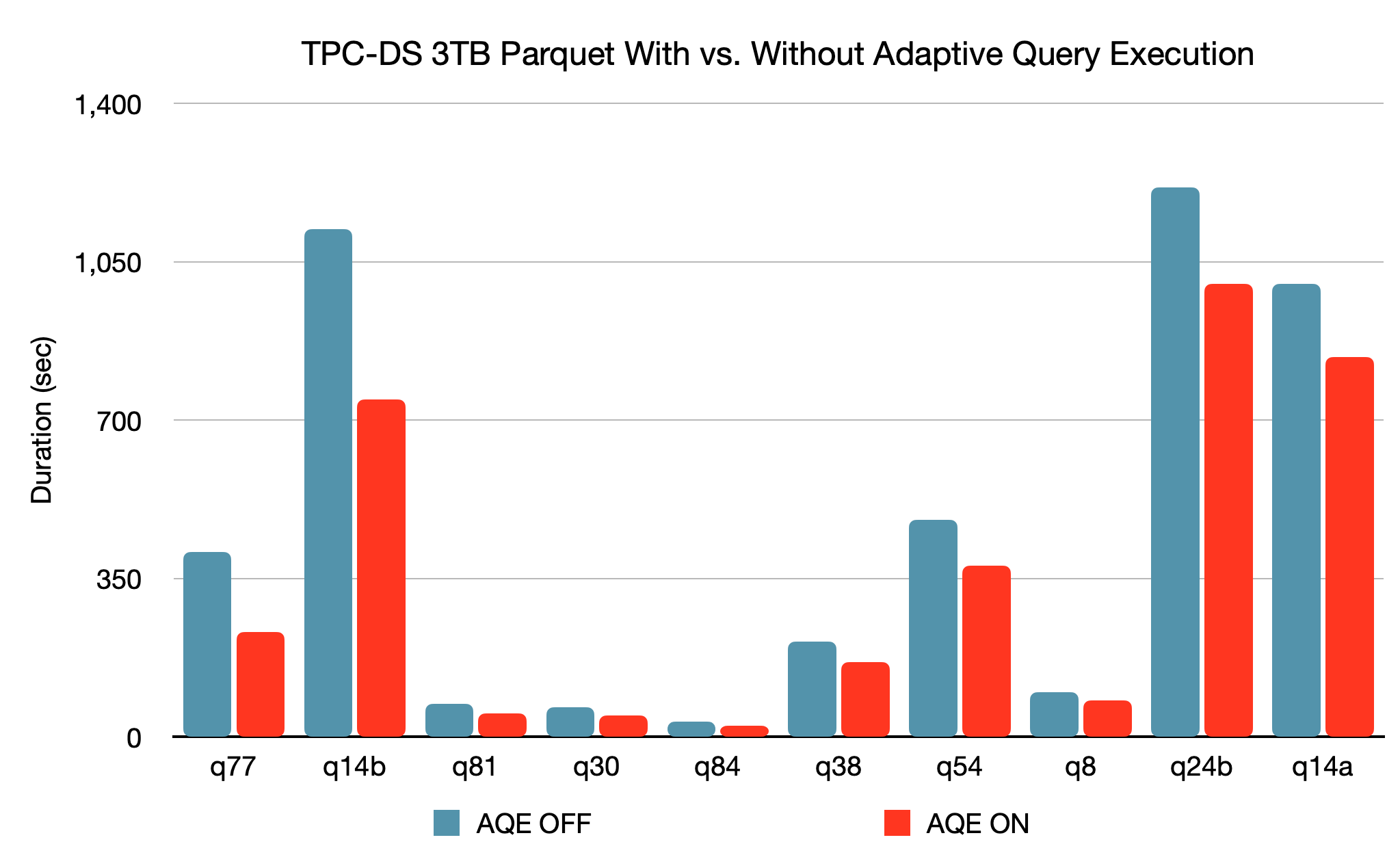
TDC-DS performance gains from AQE
Enabling AQE
- SparkSession configuration using AQE
spark.conf.set("spark.sql.adaptive.enabled", "true")
- Using shuffle partition optimization
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
Dynamic Partition Pruning[SPARK-11150]
- Goal:full scan을 피하기 위함 (필요하지 않은 데이터는 가지치기(Pruning))
- Usefilter push down to optimize query
Filter Push Down
- 일반적으로 쿼리처리: DB → full scan →filter
- Filter Push Down: Filter를 Scan보다 먼저 둬서 미리 필터링한 값을 Scan하는 방법
- 원하는 값만 읽어 성능 향상
How?
- Filter Push Down기법(filter)을 partitioned files에 적용하고, 필요한 파일만 scan
- Partitioned files: Spark 내 데이터가 partition으로 분할된 것
- Sales table (dimension table = small size table) > Countries table (fact table = large size table)
- dimension table (작은 테이블)의 필터링 결과를 fact table(큰 테이블)에 적용하여
- 큰 테이블에서 full scan하지 않고 필요한 데이터만 필터링
Query Step

- Spark에서 쿼리 실행 시 단계
- 논리적 실행 계획 (Logical Plan Optimization)
- 물리적 실행 계획 (Physical Planning)
- RDD를 이용해 실제 분산 클러스터에서 작업
- 논리적 실행 계획 단계에서 Dynamic Pruning을 적용하고, 물리적 실행 계획 단계에서 더 최적화를 시켜보자.
STEP1: Logical execution plan

- full scan 을 피하고 원하는 데이터(파란색, 초록색 데이터)만 집어 join 을 하는 것이 최적의 성능을 낼 것
→ filter(*위 그림의 Scan DIM TABLE + Filter DIM)를 partitioned file에 적용 - 쿼리(*filter인 빨간 박스 부분)가 중복되어 사용된다는 문제가 있음
→ 중복 쿼리 제거 필요 (STEP2에서)
STEP2: Physical execution plan
- broadcast hash join를 사용함으로써 중복 쿼리 문제를 해결할 수 있음
(*dim table 크기가 충분히 작아 memory에 잘 맞을 경우 좋은 퍼포먼스가 나오는 join방법)
Broadcast hash join
- build relation 값을 partition files가 full scan 하기 전에Dynamic Filter로 넣어줌
→ 원하는 데이터(파란색, 초록색 데이터)만 집어 join
→ Logical execution plan의 최적화 중에 발생한sub query 중복 해결
Conclusion

- Logical execution plan에서의 최적화: dim table의 필터를 fact table에 적용
- Physical execution plan에서의 최적화: 필터를 한번만 적용한 다음 fact table에서 result variable로 재사용
- TPC-DS에서, 102개 query 중 60개는 2x에서 18x 사이의 속도 향상을 보여줌
→ Spark doesn't make not necessary table, so performance improve in star schema queries
more: https://blog.knoldus.com/dynamic-partition-pruning-in-spark-3-0/
Enabling DPP
spark.conf.set("spark.sql.optimizer.dynamicPartitionPruning.enabled", "true")ANSI SQL compliance
다른 SQL engine에서 Spark SQL로의 workload migration할 때 중요
- [SPARK-26651] Proleptic Gregorian calendar으로 전환
(~ v2.4: hybrid calendar-Julian + Gregorian in date/timestamp parsing, functions and expressions사용) - [SPARK-26215]ALSI SQL의 예약 키워드를 식별자로 사용 금지
- [SPARK-26218][SPARK-30341]새로운 유효성 검사
: runtime overflow checking in numeric operations and compile-time type enforcement when inserting data into a table with a predefined schema - [SPARK-28989]`spark.sql.ansi.enabled`추가 (아래의 3가지 configuration을`spark.sql.ansi.enabled` 하나로 사용)
spark.sql.parser.ansi.enabled
spark.sql.decimalOperations.nullOnOverflow
spark.sql.failOnIntegralTypeOverflow- [SPARK-28885]`spark.sql.storeAssignmentPolicy` 추가
(column에 다른 데이터 타입의 값을 삽입할 때, 타입 강제 형변환 수행되기 때문에 Spark 3.0에서 configuration 새로 도입)- [SPARK-28495] v1 datasource에서는 default "Legacy", v2에서는 "Strict" → Spark 3.0에서 v1과 v2 default를 "ANSI"로 통일
Enabling ANSI Compliance
- ANSI SQL 표준 준수 (e.g., arithmetic operations, type conversion, SQL functions and SQL parsing)
spark.conf.set("spark.sql.ansi.enabled", "true")
- store assignment 규칙 준수 (default: ANSI)
spark.conf.set("spark.sql.storeAssignmentPolicy", "ANSI" or "legacy" or "strict")Other
- [SPARK-27986] Support Aggregate Expressions with filter
- [SPARK-27225] Implement join strategy hints
Enhancing the Python APIs
[SPARK-28264] New pandas APIs with type hints
background
- Spark 2.3에서 pandas UDF(User Defined Function)가 처음 도입
→ UDF 유형이 추가되고 진화됨에 따라 기존의 interface와 혼란을 야기
→python type hints를 활용해 더 python스럽고 자체 설명이 되는 Pandas UDF용 interface 도입 - pandas type hints(pandas.Series, pandas.DataFrame, Tuple 및 Iterator...)를 사용해 새로운 Pandas UDF 유형 표현
기존의 Spark 2.3 예시 (* 3가지 모두 동일한 결과)
-> 각각의 Pandas UDF는 서로 다른입출력 type을 예상해 각각 구별되고 다른 퍼포먼스로 작동 → 사용 방법과 작동 방식 혼란 야기
- PandasUDFType.SCALAR
@pandas_udf('long', PandasUDFType.SCALAR)
def pandas_plus_one(v):
# `v` is a pandas Series
return v + 1 # outputs a pandas Series
spark.range(10).select(pandas_plus_one("id")).show()
- PandasUDFType.SCALAR_ITER
# New type of Pandas UDF in Spark 3.0.
@pandas_udf('long', PandasUDFType.SCALAR_ITER)
def pandas_plus_one(itr):
# `iterator` is an iterator of pandas Series.
return map(lambda v: v + 1, itr)
# outputs an iterator of pandas Series.
spark.range(10).select(pandas_plus_one("id")).show()
- PandasUDFType.GROUPED_MAP
@pandas_udf("id long", PandasUDFType.GROUPED_MAP)
def pandas_plus_one(pdf):
# `pdf` is a pandas DataFrame
return pdf + 1 # outputs a pandas DataFrame
# `pandas_plus_one` can _only_ be used with `groupby(...).apply(...)`
spark.range(10).groupby('id').apply(pandas_plus_one).show()New types of pandas UDFs and pandas function APIs
- 기존의 Padas UDFs를 2개의 API로 분리 → Pandas UDFs & Pandas Function APIs
- 내부적으로는 비슷한 방식으로 작동하지만 차이점 존재
- Pandas UDFs: 다른 PySpark column instances에서 사용하는 것과 같은 방법으로 처리
- Pandas Function APIs: column instances에 사용 불가
- 새로운 pandas UDF type 추가 (*useful for data prefetching and expensive initialization)
- iterator of series to iterator of series
- iterator of multiple series to iterator of series
- 새로운 pandas-function APIs 추가
- map
- co-grouped map
+) Better error handling
- 불필요한 JVM stack trace를 숨기고, pythonic하게 수정
Hydrogen, streaming and extensibility
- Project Hydrogen의 주요 components 완료
- streaming과 확장성을 개선하는 새로운 기능 도입
Project Hydrogen
Spark에서 딥러닝 및 데이터 처리를 더 통합하는 것이 목적
[SPARK-24615] Accelerator-aware task scheduling for Spark
Background and Motivation
- 대규모 datasets를 로드하거나 처리하고, streaming과 같은 복잡한 data scenario를 처리하려면 Apache Spark 필요
- YARN, Kubernetes는 이미 최근 Release에서 GPU 지원 (*YARN, Kubernetes는 Cluster manager)
- Spark는 YARN과 Kuberenetes를 지원하지만, GPU를 인식하지 못해 GPU를 올바르게 요청하거나 schedule할 수 없음
Goal
- Spark가 GPU를 인식하도록 2가지 변경 진행
- cluster manager 수준에서 GPU support가 포함되도록 cluster manager를 업데이트하거나 업그레이드
그 이후에 Spark용 user interfaces를 노출해 GPU 요청 - Spark 내에서 scheduler를 업데이트하여 실행자와 사용자 작업 요청에 할당된 사용가능한 GPU를 이해하고 올바르게 GPU를 작업에 할당
- cluster manager 수준에서 GPU support가 포함되도록 cluster manager를 업데이트하거나 업그레이드
Target Personas
- Admins who need to configure clusters to run Spark with GPU nodes.
- Data scientists who need to build DL applications on Spark.
- Developers who need to integrate DL features on Spark.
Summary
- cluster manager가 accelerator를 인식하도록 기존의 scheduler 향상
- configuration을 통해 accelerator 지정 가능
- 새로운 RDD APIs를 호출해 accelerator를 활용
[SPARK-29543] New UI for structured streaming
Streaming 작업 검사 용 새 Spark UI추가
- 완료된 Streaming query 작업의 집계 정보
- Streaming query에 대한 자세한 통계 정보
포함된 메트릭
- Input Rate.The aggregate (across all sources) rate of data arriving.
- Process Rate.The aggregate (across all sources) rate at which Spark is processing data.
- Input Rows.The aggregate (across all sources) number of records processed in a trigger.
- Batch Duration.The process duration of each batch.
- Operation Duration.The amount of time taken to perform various operations in milliseconds. The tracked operations are listed as follows.
- addBatch: Adds result data of the current batch to the sink.
- getBatch: Gets a new batch of data to process.
- latestOffset: Gets the latest offsets for sources.
- queryPlanning: Generates the execution plan.
- walCommit: Writes the offsets to the metadata log.
(* 초기 release 버전으로 향후에 더 개선될 예정)
[SPARK-29345] Observable metrics
- batch 및 streaming query에 대해 임의의 metrics을 정의하고 monitoring할 수 있는 api 추가
- 관찰가능한 metrics:Query(DataFrame)에 정의할 수 있는 임의의 aggregate 함수
- DataFrame 실행이 완료 지점(e.g., batch query가 완료하거나 streaming epoch에 도달)에 도달하면,
마지막 완료 지점 이후 처리된 데이터에 대한 metrics을 포함한 지정된 이벤트가 생성
- DataFrame 실행이 완료 지점(e.g., batch query가 완료하거나 streaming epoch에 도달)에 도달하면,
[SPARK-31121]New catalog plug-in API
- 기존의 datasource API는 external datasource의 메타 데이터에 액세스하고 조작하는 기능이 없음
- datasource V2 API를 강화하고 새 catalog plug-in API를 추가
- 두 API를 모두 구현하는 external data sources에서 사용자는 해당 external catalog를 등록한 후 multipart identifiers를 통해 external table의 데이터와 메타데이터를 모두 직접 조작할 수 있음
Data Source API
Storage System에(서) 어떻게 데이터를 쓰고 읽는지 정의하는 API
예를 들어 Hadoop은 InputFormat/OutputFormat, Hive는 Serde, Presto는 Connector 등의 Data Source API를 가지고 있다.
Multipart identifier
Any description of a field or table that contains multiple parts - for instance MyTable.SomeRow
Other updates in Spark 3.0
- [SPARK-24417] Java 11 support
- [SPARK-23534] Hadoop 3 support
... (3400 Jira tickets resolved)
Deprecations
- Deprecate Python 2 support (SPARK-27884)
- Deprecate R < 3.4 support (SPARK-26014)
- Deprecate UserDefinedAggregateFunction (Spark-30423)
Appendix
- https://spark.apache.org/releases/spark-release-3-0-0.html
- https://nephtyws.github.io/data/whats-new-in-spark-3/
- https://databricks.com/blog/2020/06/18/introducing-apache-spark-3-0-now-available-in-databricks-runtime-7-0.html#
- https://www.slideshare.net/databricks/whats-new-in-the-upcoming-apache-spark-30
- https://eyeballs.tistory.com/245
'개발 > Hadoop eco-system' 카테고리의 다른 글
| [Hadoop] HiveServer2 (0) | 2023.01.13 |
|---|---|
| [HBase] Online Region Merge와 Empty Region Merge에 대해 (0) | 2022.06.30 |
| Impala Query Performance - EXPLAIN 계획과 Query 프로파일 (0) | 2021.11.11 |
| CDH6 HBase2 X Impala2 쿼리 튜닝 (0) | 2021.11.11 |
| Apache Hadoop (v1 특징, v2 특징, yarn 아키텍처, HDFS, 맵리듀스) (1) | 2020.11.24 |


댓글